- Published on
文本转语音如此简单
- Authors

- 作者
- 狂奔滴小马

前言
哈喽,大家好,我是小马,这两天在研究文本转音的功能,有时候担心自己的普通话不标准,比方说要录制一个视频,即兴讲可能会卡壳,这个时候我们就可以先准备好文本,然后再利用人工智能来生成音频,下面就分享下我的研究成果吧!
语音合成 Text To Speech
实现原理
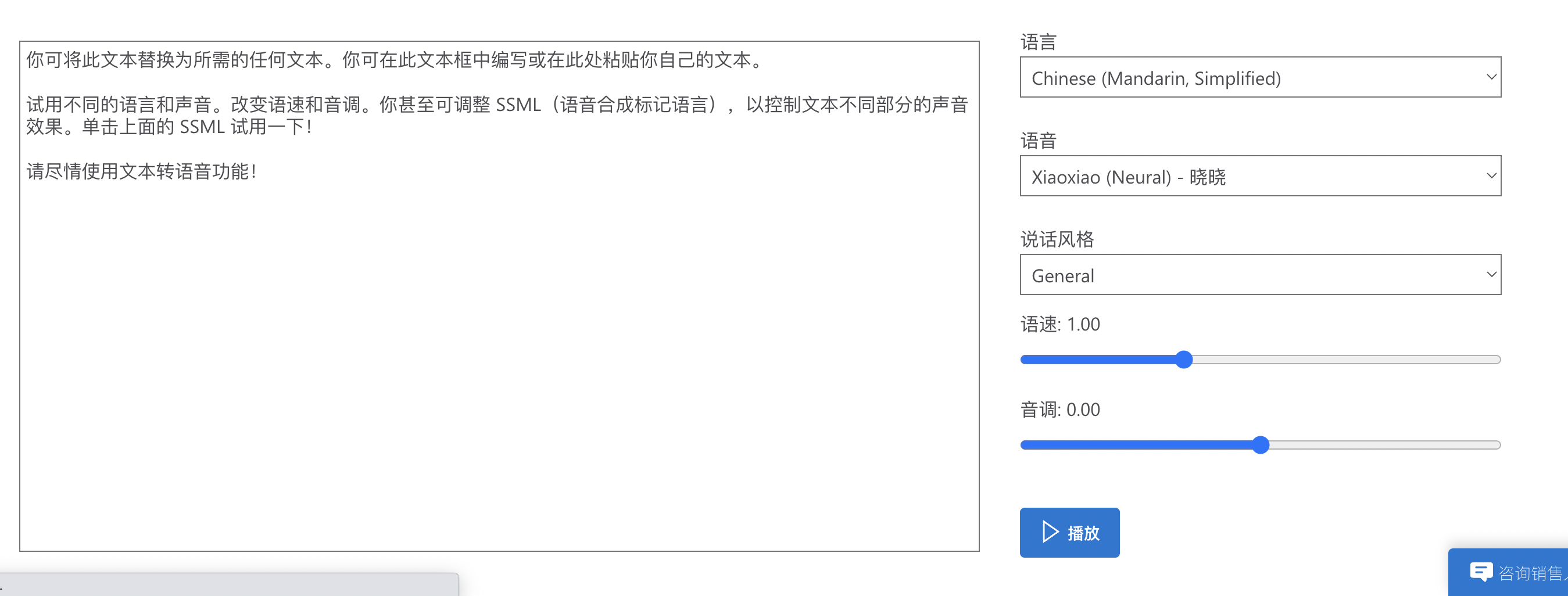
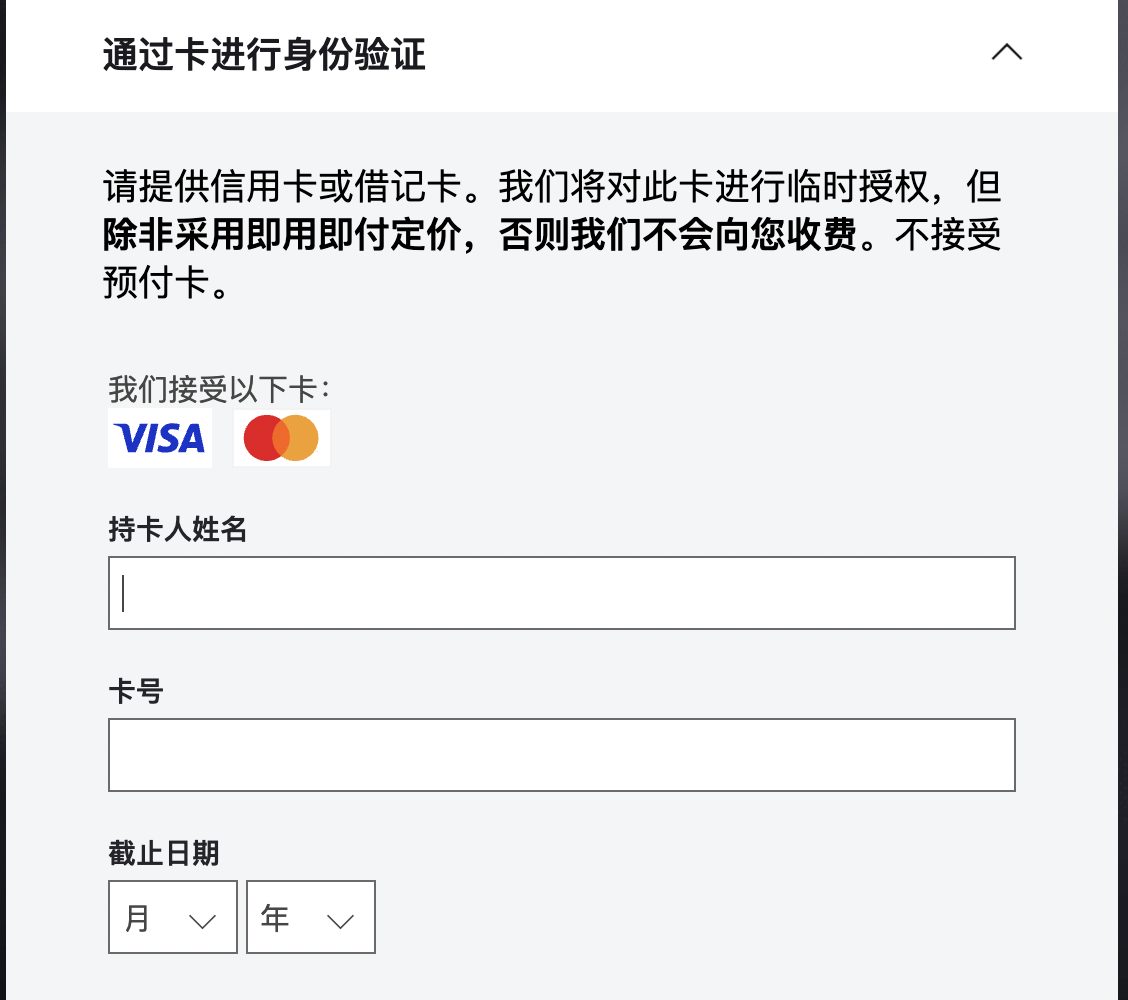
使用
首先:需要安装 chrome 油猴扩展,然后再安装这个脚本;
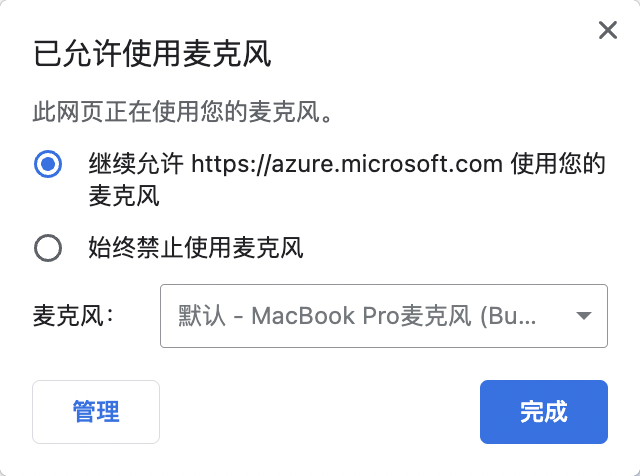
第二步:开始录音的时候,在 chrome 上方要允许录音,mac 电脑若没录音过,还需要在设置权限中开启权限。
第三步:输入你想要的文本,先点击播放,然后在点击开始,就会录音,点停止录音,然后就可以下载了音频文件了。
SSML 语法
在录制文本由此有个 Tab 标签, SSML 是语音合成标记语言,跟 HTML 一样是 XML,但却可以描述语音的改善合成,比如音节、发音、语速、音量。
使用多个语音
比如下面的代码,就可以模拟 2 个人的对话
<speak xmlns="http://www.w3.org/2001/10/synthesis" xmlns:mstts="http://www.w3.org/2001/mstts" xmlns:emo="http://www.w3.org/2009/10/emotionml" version="1.0" xml:lang="en-US">
<voice name="en-US-JennyNeural">Good morning!</voice>
<voice name="en-US-ChristopherNeural">Good morning to you too Jenny!</voice>
</speak>
调整讲话风格
可使用 mstts:express-as 元素来表达情感(例如愉悦、同情和冷静)。 也可以针对不同场景(例如客户服务、新闻广播和语音助理)优化语音。
<speak version="1.0" xmlns="http://www.w3.org/2001/10/synthesis"
xmlns:mstts="https://www.w3.org/2001/mstts" xml:lang="en-US">
<voice name="en-US-AriaNeural">
<mstts:express-as style="cheerful">
That'd be just amazing!
</mstts:express-as>
</voice>
</speak>
调整讲话语言
通过 <lang xml:lang="es-US"> 修改语言
<speak version="1.0" xmlns="http://www.w3.org/2001/10/synthesis"
xmlns:mstts="https://www.w3.org/2001/mstts" xml:lang="en-US">
<voice name="zh-CN-XiaoxiaoNeural">
欢迎关注微信公众号JS酷,英语是
<lang xml:lang="es-US">
Welcome to follow wechat public account JS cool
</lang>
</voice>
</speak>
风格强度
可调整讲话风格的强度,更好地适应你的使用场景。 可以使用 styledegree 属性指定更强或更柔和的风格,使语音更具表现力或更柔和。 中文(普通话,简体)神经语音支持讲话风格强度调整。
<speak version="1.0" xmlns="http://www.w3.org/2001/10/synthesis"
xmlns:mstts="https://www.w3.org/2001/mstts" xml:lang="zh-CN">
<voice name="zh-CN-XiaoxiaoNeural">
<mstts:express-as style="sad" styledegree="2">
快走吧,路上一定要注意安全,早去早回。
</mstts:express-as>
</voice>
</speak>
添加暂停
<speak version="1.0" xmlns="http://www.w3.org/2001/10/synthesis" xml:lang="en-US">
<voice name="en-US-JennyNeural">
Welcome to Microsoft Cognitive Services <break time="100ms" /> Text-to-Speech API.
</voice>
</speak>
指定段落和句子
p 和 s 元素分别用于表示段落和句子
<speak version="1.0" xmlns="http://www.w3.org/2001/10/synthesis" xml:lang="en-US">
<voice name="en-US-JennyNeural">
<p>
<s>Introducing the sentence element.</s>
<s>Used to mark individual sentences.</s>
</p>
<p>
Another simple paragraph.
Sentence structure in this paragraph is not explicitly marked.
</p>
</voice>
</speak>
更多内容大家可以参考官方文档
应用例子
周末到了,学习的同时也该放松下,一起来欣赏一个视频吧
我是怎么做的? 先在预告片网站下载一个预告片,然后是去找简介,转成音频后,然后再合成视频。
你是否明白了什么?抖音上很多视频都是靠搬运 ➕AI 配音就成了原创视频。
<speak
version="1.0"
xmlns="http://www.w3.org/2001/10/synthesis"
xmlns:mstts="https://www.w3.org/2001/mstts"
xml:lang="en-US"
>
<voice name="zh-CN-XiaoxiaoNeural">
<p>
<w>长津湖之水门桥</w>是由陈凯歌、徐克、林超贤监制,<w>徐克</w>执导,吴京、易烊千玺领衔主演的战争电影。
</p>
<p>
该片以抗美援朝战争第二次战役中的长津湖战役为背景,讲述在结束了新兴里和下碣隅里的战斗之后,七连战士们又接到了更艰巨的任务的故事
</p>
<p>
<w>长津湖之水门桥</w
>作为电影<w>长津湖</w>的续集,讲述了七连战士们在结束了新兴里和下碣隅里的战斗之后,又将面临更艰巨的挑战和更猛烈的火力,他们将在美陆战一师撤退路线上的咽喉之处——水门桥阻击敌军,任务会更加艰巨,战斗场面会更加激烈,为赢得胜利付出的巨大牺牲也会令人更加动容。
</p>
</voice>
</speak>
音频
小结
1、目前由于 navigator.mediaDevices.getDisplayMedia() 还不能直接录制电脑的声音,必须电脑将声音外放,然后录音,所以录音需要找个安静的环境。
2、有时候网速不好可能会卡,需要找个好点的网络,我后面是用的手机热点,一点也没卡。
以上就是本文全部内容,希望这篇文章对大家有所帮助,也可以参考我往期的文章或者在评论区交流你的想法和心得,欢迎一起探索前端。
[1]阿里云的语音合成: https://ai.aliyun.com/nls/tts
[2]腾讯云的语音合成: https://cloud.tencent.com/product/tts
[3]微软的 TTS: https://azure.microsoft.com/zh-cn/services/cognitive-services/text-to-speech/#overview
